from IPython.display import Image
Image(filename='images/paper_image.png')
from IPython.display import Image
Image(filename='images/paper_image.png')
Target-Dependent Sentiment Classification is one of the text classification problems in the field of sentiment analysis. Given a sentence and a target to the model, it has to output the sentiment polarity (e.g positive, negative, neutral) of the sentence towards that target. For example, we have a sentence “I bout a new camera. The pucture quality is amazing but the battery life is too short”. If we input the target picture quality, we expect the sentiment to be “positive”. On the other hand, if we input the target battery life, we expect the sentiment to be “negative”.
The author argues that the Target-Dependent sentiment classification is challenging since it is hard to effectively model the sentiment relatedness of a target word with its context words in a sentence. Doing feature engineerings are clumsy, so they propose a neural network approach with 2 models Target-Dependent LSTM (TD-LSTM) and Target-Connection LSTM(TC-LSTM).
In this post, I will implement those models and compare it with the plain LSTM model, just like they did. Yet, I will not cover other approaches using SVM and RNN. Since in the original paper, the author did not provide the specific hyper-parameters they used for their models, I will fine-tune it on my own.
This post covers the data processing step and the implementation of TD-LSTM. The second post will cover the implementation of TC-LSTM and comparision between three models: TC-LSTM, TD-LSTM, and LSTM.
The full notebook is available here.
%%capture
!pip install pytorch-lightning
!pip install torchmetrics
# !pip install transformersFirst of all you should download the dataset. The dataset used in the paper is from the Twitter (Dong et al., 2014). You can download from here. After downloading, you should unzip the dataset file in the same folder with the notebook. They should be in the same folder to run properly.
%%capture
!unzip acl-14-short-data.zipIn the paper, the author used the 100-dimensional Glove vectors learned from Twitter. Download the word embedding file and unzip it in the same folder with the notebook.
%%capture
!wget https://nlp.stanford.edu/data/glove.twitter.27B.zip
!unzip glove.twitter.27B.zipimport numpy as np
import pytorch_lightning as pl
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchmetrics
from pytorch_lightning import loggers as pl_loggers
from pytorch_lightning.callbacks import ModelCheckpoint
from torch.utils.data import DataLoader, Dataset, random_split
from torchtext.data import get_tokenizer=====Dataset File Format=====
Each instance consists three lines: - sentence (the target is replaced with \(T\)) - target - polarity label (0: neutral, 1:positive, -1:negative)
Example:
i agree about arafat . i mean , shit , they even gave one to \(T\) ha . it should be called ’’ the worst president ’’ prize .
jimmy carter
-1
Target-Dependent LSTM (TD-LSTM)
The LSTM model solves target-dependent sentiment classification in a target- independent way. That is to say, the feature representation used for sentiment classification remains the same without considering the target words. Let us again take “I bought a new camera. The picture quality is amazing but the battery life is too short” as an example. The representations of this sentence with regard to picture quality and battery life are identical. This is evidently problematic as the sentiment polarity labels towards these two targets are different.
To take into account of the target information, we make a slight modification on the aforementioned LSTM model and introduce a target-dependent LSTM (TD-LSTM) in this subsection. The basic idea is to model the preceding and following contexts surrounding the target string, so that contexts in both directions could be used as feature representations for sentiment classification. We believe that capturing such target-dependent context information could improve the accuracy of target-dependent sentiment classification.
Specifically, we use two LSTM neural networks, a left one LSTML and a right one LSTMR, to model the preceding and following contexts respectively. An illustration of the model is shown in Figure 1. The input of LSTML is the preceding contexts plus target string, and the input of LSTMR is the following contexts plus target string. We run LSTML from left to right, and run LSTMR from right to left. We favor this strategy as we believe that regarding target string as the last unit could better utilize the semantics of target string when using the composed representation for sentiment classification. Afterwards, we concatenate the last hidden vectors of LSTML and LSTMR , and feed them to a sof tmax layer to classify the sentiment polarity label. One could also try averaging or summing the last hidden vectors of LSTML and LSTMR as alternatives.
from IPython.display import Image
Image(filename='images/firgure_1_image.png')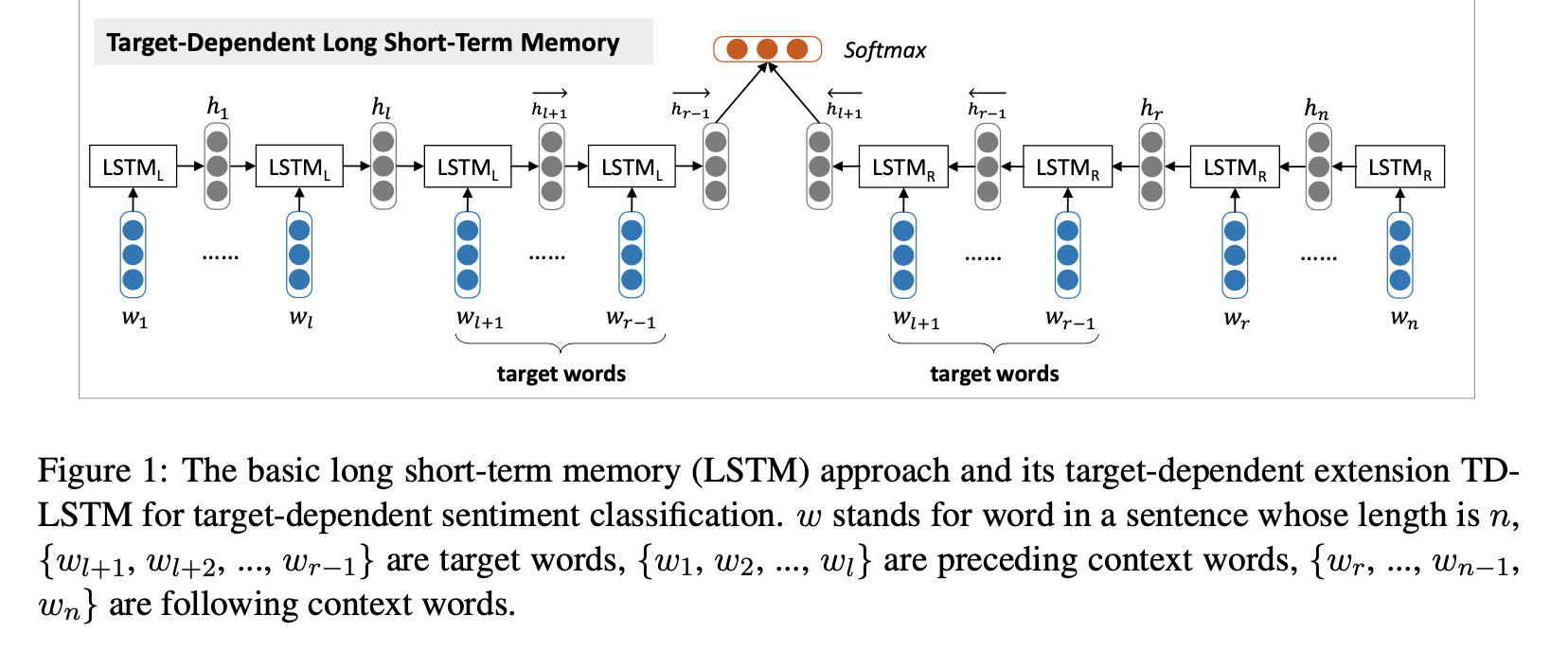
class TwitterTDLSTMDataset(Dataset):
def __init__(self, l_sequences, r_sequences, l_lens, r_lens, sentiments):
self.l_sequences = l_sequences
self.r_sequences = r_sequences
self.l_lens = l_lens
self.r_lens = r_lens
self.sentiments = sentiments
def __len__(self):
return len(self.sentiments)
def __getitem__(self, idx):
return (self.l_sequences[idx], self.l_lens[idx]), (self.r_sequences[idx], self.r_lens[idx]), self.sentiments[idx]# Read file
def create_dataset_from(path: str):
"""
Create a dataset from a file path
Return: a TwitterDataset object
"""
sentences = []
targets = []
sentiments = []
with open(path) as f:
lines = f.readlines()
# Read the file line by line and
# check the relative index to parse the data according to the format.
for i, line in enumerate(lines):
index = i % 3 # compute the relative index
if index == 0: sentences.append(line[:-1])
elif index == 1: targets.append(line[:-1])
elif index == 2: sentiments.append(line.strip())
#Load tokenizer
tokenizer = get_tokenizer("basic_english")
#Tokenize and Lower sentence and target text
tokenized_sentences = list(map(lambda x: tokenizer(x), sentences))
targets = list(map(lambda x: tokenizer(x), targets))
#Convert sentiment text to number
sentiments = list(map(lambda x: int(x), sentiments))
#Generate sequence_l, sequence_r
l_sequences = []
r_sequences = []
for i, sent in enumerate(tokenized_sentences):
seq_l, seq_r = [], []
flag = True
for token in sent:
if word_2_id.get(token) == len(word_2_id) - 1:
flag = False
continue
if flag:
# get the index of the token in the vocab
# if the token does not exists in the vocab, return index of <UNK> token
seq_l.append(word_2_id.get(token, 1))
else:
seq_r.append(word_2_id.get(token, 1))
target_seq = [word_2_id.get(token, 1) for token in targets[i]]
seq_l = torch.tensor(seq_l + target_seq)
seq_r = torch.tensor((target_seq + seq_r)[::-1]) # reverse the seq_r
l_sequences.append(seq_l)
r_sequences.append(seq_r)
l_lens = torch.tensor([len(seq) for seq in l_sequences])
r_lens = torch.tensor([len(seq) for seq in r_sequences])
sentiments = torch.tensor(sentiments) + 1
assert len(l_lens) == len(l_sequences)
assert len(r_lens) == len(r_sequences)
assert len(l_lens) == len(sentiments)
return TwitterTDLSTMDataset(l_sequences, r_sequences, l_lens, r_lens, sentiments)def load_w2v(embedding_file_path: str):
"""
Load pretrained word-embeddings from a file path
Return a word_2_id dictionary and a embedding matrix
"""
word_2_id = {'<PAD>': 0, '<UNK>': 1}
embeddings = [torch.zeros(100), torch.zeros(100)]
with open(embedding_file_path) as f:
for i, line in enumerate(f.readlines()):
tokens = line.split()
word, vec = ' '.join(tokens[:-100]), tokens[-100:]
word_2_id[word] = i + 2
# convert list of str to float
float_tokens = np.array(vec, dtype=float)
embeddings.append(torch.tensor(float_tokens, dtype=torch.float))
embeddings = torch.stack(embeddings)
embeddings[word_2_id['<UNK>']] = torch.mean(embeddings[2:], dim=0)
word_2_id['$t$'] = len(word_2_id)
return word_2_id, embeddings# Create word_2_di dictionary and embeddings matrix
word_2_id, embeddings = load_w2v("glove.twitter.27B.100d.txt")# Create a collate_batch function to
from torch.nn.utils.rnn import pad_sequence, pack_padded_sequence, pad_packed_sequence
def collate_batch(batch):
"""
Combine samples from dataset into a batch
"""
l_sequences = []
l_lens = []
r_sequences = []
r_lens = []
sentiments = []
for (l_sequence, l_len), (r_sequence, r_len), sentiment in batch:
l_sequences.append(l_sequence)
l_lens.append(l_len)
r_sequences.append(r_sequence)
r_lens.append(r_len)
sentiments.append(sentiment)
padded_l_seq = pad_sequence(l_sequences, batch_first=True, padding_value=0)
padded_r_seq = pad_sequence(r_sequences, batch_first=True, padding_value=0)
return (padded_l_seq, l_lens), (padded_r_seq, r_lens), torch.tensor(sentiments)In the paper, the author trained the model on training set, and evaluated the performance on test set
dataset = create_dataset_from("/content/acl-14-short-data/train.raw")
dataloaders = DataLoader(dataset, batch_size=128, collate_fn=collate_batch)test_dataset = create_dataset_from("/content/acl-14-short-data/test.raw")
test_dataloaders = DataLoader(test_dataset, batch_size=64, collate_fn=collate_batch)The architecture has a embedding layer, 2 LSTM layers and 1 dense layer.
Convert the sequences to word vectors using pre-trained Glove word embeddings
One layer is used for the [left context + target] sequences, and one is used for the [target + right context] sequences.
We concate the 2 hidden states from the LSTM layers and feed it into the Dense layer.
Notes:
We use Adam as our optimizer and using accuracy and f1 as our evaluating metrics, just like in the original paper.
class TDLSTM(pl.LightningModule):
def __init__(self, embeddings, hidden_size, num_layers=1, num_classes=3, batch_first=True, lr=1e-3, dropout=0, l2reg=0.01):
super().__init__()
embedding_dim = embeddings.shape[1]
self.embedding = nn.Embedding.from_pretrained(embeddings) # load pre-trained word embeddings
self.l_lstm = nn.LSTM(embedding_dim, hidden_size, num_layers, batch_first=batch_first, dropout=dropout)
self.r_lstm = nn.LSTM(embedding_dim, hidden_size, num_layers, batch_first=batch_first, dropout=dropout)
self.linear = nn.Linear(hidden_size*2, num_classes)
self.lr = lr
self.l2reg = l2reg
# Define metrics
self.train_acc = torchmetrics.Accuracy()
self.val_acc = torchmetrics.Accuracy()
self.val_f1 = torchmetrics.F1(num_classes=3, average='macro')
self.test_acc = torchmetrics.Accuracy()
self.test_f1 = torchmetrics.F1(num_classes=3, average='macro')
def configure_optimizers(self):
optim = torch.optim.AdamW(self.parameters(), lr=self.lr, weight_decay=self.l2reg)
return optim
def forward(self, padded_l_seqs, l_lens, padded_r_seqs, r_lens):
# convert seq to word vector
padded_l_embeds = self.embedding(padded_l_seqs)
padded_r_embeds = self.embedding(padded_r_seqs)
# pack the embeds
padded_l_seq_pack = pack_padded_sequence(padded_l_embeds, l_lens, batch_first=True, enforce_sorted=False)
padded_r_seq_pack = pack_padded_sequence(padded_r_embeds, r_lens, batch_first=True, enforce_sorted=False)
_, (h_l, _) = self.l_lstm(padded_l_seq_pack)
_, (h_r, _) = self.r_lstm(padded_r_seq_pack)
h = torch.cat((h_l[-1], h_r[-1]), -1) # B x 2H
out = self.linear(h)
return out
def training_step(self, batch, batch_idx): # pylint: disable=unused-argument
(padded_l_seqs, l_lens), (padded_r_seqs, r_lens), sentiments = batch
logits = self.forward(padded_l_seqs, l_lens, padded_r_seqs, r_lens)
loss = F.cross_entropy(logits, sentiments)
scores = F.softmax(logits, dim=-1)
self.train_acc(scores, sentiments)
self.log('train_loss', loss, on_step=True, on_epoch=True, prog_bar=True)
self.log('train_acc', self.train_acc, on_step=False, on_epoch=True, prog_bar=True, logger=True)
return loss
def validation_step(self, batch, batch_idx): # pylint: disable=unused-argument
(padded_l_seqs, l_lens), (padded_r_seqs, r_lens), sentiments = batch
logits = self.forward(padded_l_seqs, l_lens, padded_r_seqs, r_lens)
loss = F.cross_entropy(logits, sentiments)
scores = F.softmax(logits, dim=-1)
self.val_acc(scores, sentiments)
self.val_f1(scores, sentiments)
self.log('val_loss', loss, on_step=True, on_epoch=True, prog_bar=True)
self.log('val_acc', self.val_acc, on_step=False, on_epoch=True, prog_bar=True, logger=True)
self.log('val_f1', self.val_f1, on_step=False, on_epoch=True, prog_bar=True, logger=True)
def test_step(self, batch, batch_idx): # pylint: disable=unused-argument
(padded_l_seqs, l_lens), (padded_r_seqs, r_lens), sentiments = batch
logits = self.forward(padded_l_seqs, l_lens, padded_r_seqs, r_lens)
scores = F.softmax(logits, dim=-1)
self.test_acc(scores, sentiments)
self.test_f1(scores, sentiments)
self.log('test_acc', self.test_acc, on_step=False, on_epoch=True, logger=True)
self.log('test_f1', self.test_f1, on_step=False, on_epoch=True, logger=True)checkpoint_callback = ModelCheckpoint(
monitor='val_acc', # save the model with the best validation accuracy
dirpath='checkpoints',
filename='best_model',
mode='max',
)
tb_logger = pl_loggers.TensorBoardLogger('logs/') # create logger for tensorboard
# hyper-parameters
lr = 1e-3
hidden_size = 500
num_epochs = 60
l2reg = 0.5
trainer = pl.Trainer(gpus=1, max_epochs=num_epochs, logger=tb_logger, callbacks=[checkpoint_callback])
model = TDLSTM(embeddings, hidden_size, lr=lr, l2reg=l2reg)
trainer.fit(model, dataloaders, test_dataloaders)GPU available: True, used: True
TPU available: False, using: 0 TPU cores
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
----------------------------------------
0 | embedding | Embedding | 119 M
1 | l_lstm | LSTM | 1.2 M
2 | r_lstm | LSTM | 1.2 M
3 | linear | Linear | 3.0 K
4 | train_acc | Accuracy | 0
5 | val_acc | Accuracy | 0
6 | val_f1 | F1 | 0
7 | test_acc | Accuracy | 0
8 | test_f1 | F1 | 0
----------------------------------------
2.4 M Trainable params
119 M Non-trainable params
121 M Total params
487.050 Total estimated model params size (MB)# load the best model
new_model = TDLSTM.load_from_checkpoint(checkpoint_callback.best_model_path, embeddings=embeddings, hidden_size=500)
trainer.test(new_model, test_dataloaders)LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
--------------------------------------------------------------------------------
DATALOADER:0 TEST RESULTS
{'test_acc': 0.7037572264671326, 'test_f1': 0.6847572326660156}
--------------------------------------------------------------------------------[{'test_acc': 0.7037572264671326, 'test_f1': 0.6847572326660156}]from IPython.display import Image
Image(filename='images/results.png')
Compare to the result from the paper, our implementation gets very close results. You can try to tune the model to get better result.